One of the hardest problems with RSS feeds is displaying full content. It’s essentially an unsolvable problem given the complexity of webpages and the lack of adherence to a semantic layout for any given blog or news site. It would be nice if each page had a header tag, and an article tag, but it’s not that simple. Full content parsers attempt to solve this, but each has their own set of trade-offs.
Legacy Contenders
Tools like Mozilla’s Readability.js used to solve this in the past, but given their recent woes it’s hard to trust it as a tool. Postlight Parser née Mercury Parser was a better option. Instead of trying to solve all webpages with a set of common heuristics, each domain could be overridden with a custom parser. In effect, The Verge could have a Verge-specific parser while Ars Technica could have a slightly different parser.
It would be simple to stop there, but Postlight Parser was a product of its time. Around 2015, there was a push by Google to speed up the web by simplifying webpages with AMP. Postlight was one of many companies that stepped in with their own set of tools like the parser to improve development with AMP. But as time passed, AMP fell out of fashion, and Postlight was acquired by NTT Data.
Postlight Parser essentially ended with the acquisition. It’s still possible to find Postlight Parser in the wild, however. Feedbin, a web-based feed reader, uses Postlight Parser to power its full content mode. Core development has ground to a halt with the last release in 2022.
A New Entrant
Readability.js and Postlight Parser may very well represent the past of full content extraction. However a new project called Defuddle might take their place. Defuddle was released in early 2025 by the developer behind the note-taking app Obsidian. It takes the Readability.js route of a one-size-fits-all input function with different internal heuristics.
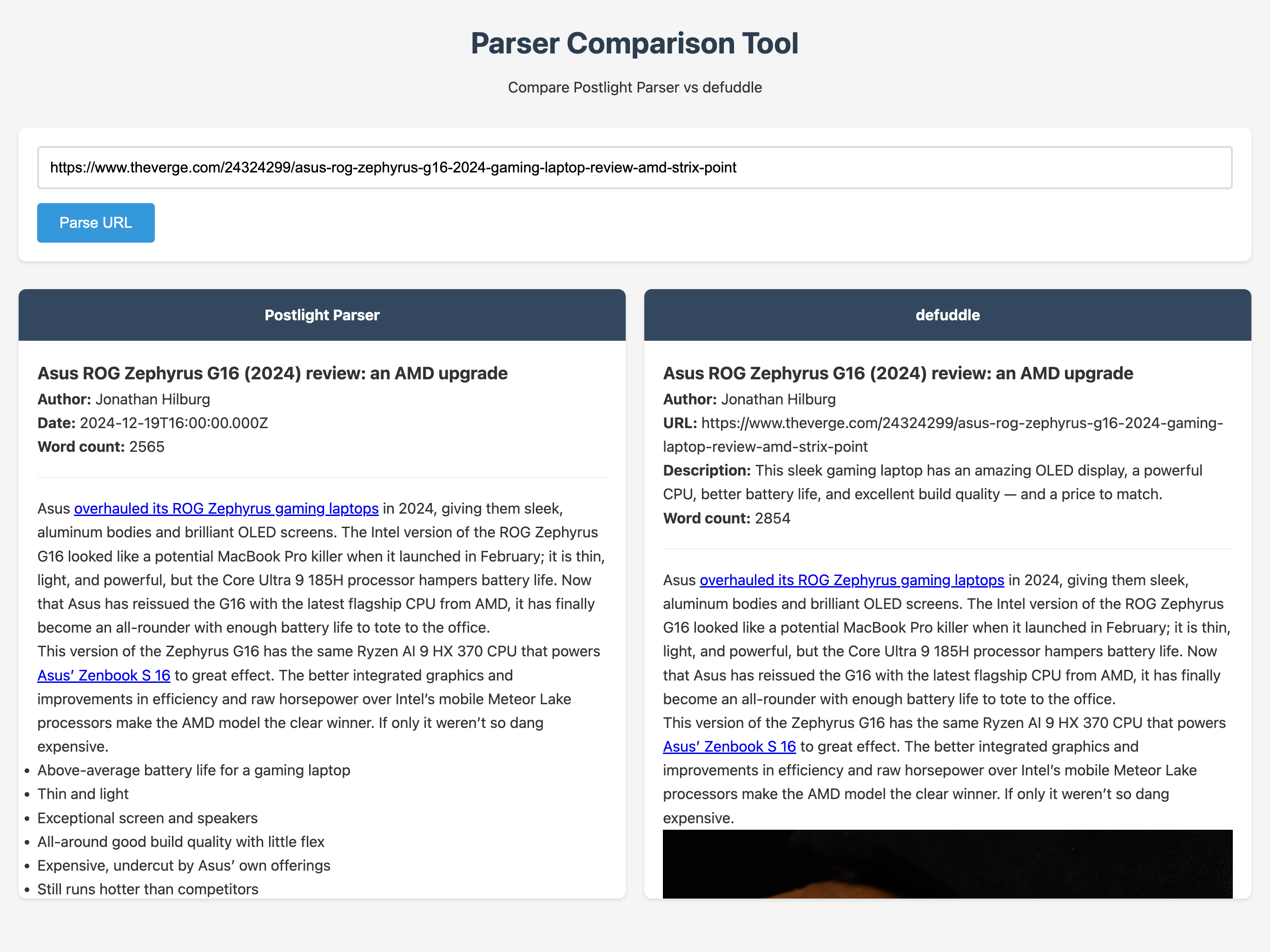
The following is a brief and non-exhaustive comparison between v2.2.3 of Postlight Parser and v0.6.4 of Defuddle using a small node.js application (source code on GitHub). Defuddle seems to work best when the site’s markup is already well formatted which is the case with The Verge. In the following review article, Defuddle picks up more images, headers, and content like the overall review score than Postlight Parser.
Parsing fails if you throw an article from Yahoo News Singapore at either Defuddle or Postlight Parser. Defuddle has a slight edge in that it at least extracts images and article content but still captures garbage text like “ADVERTISEMENT.”
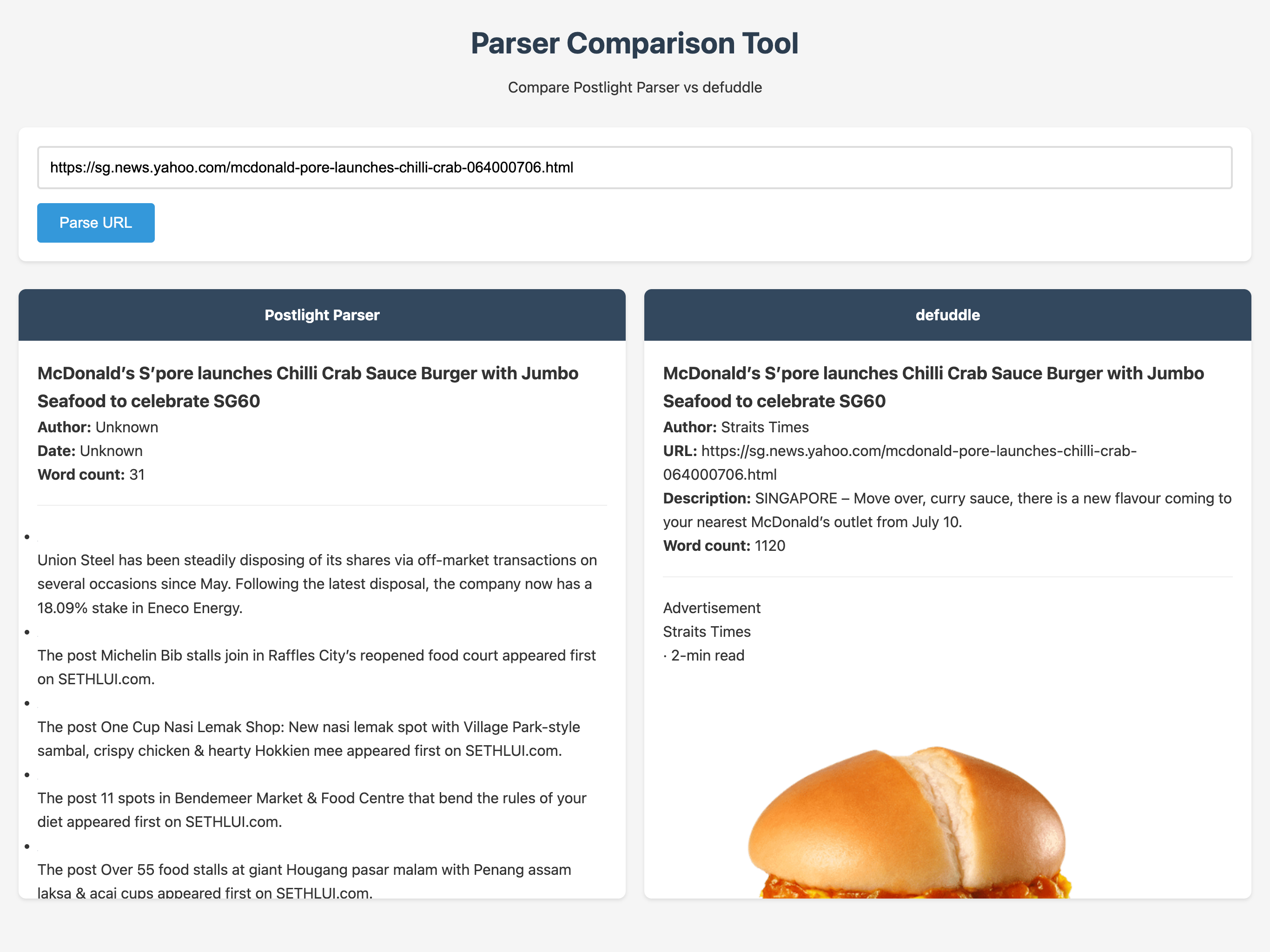
In short, better base markup still results in a better outcome. Defuddle is clearly the project to watch given Postlight Parser’s lack of updates, and it’s backed by a live project with Obsidian. Full content parsers come and go but the need to tame the chaos of the web is never ending.